PandaDB organizes data with an intelligent property graph model. The underlying data is divided into three parts: graph structure data, structured property data, and unstructured property data. Among them, graph structure data refers to data describing the structure of the graph such as the nodes and edges of the graph. Structured property data refers to data such as numerical values, strings, and dates. Unstructured property data generally refers to data except structured data, such as videos, audios, photos and documents. PandaDB stores unstructured data in the form of BLOB objects and represents them as properties of entities (nodes). According to the application characteristics of the above three types of data, PandaDB has designed a distributed multi-storage plan.
- Distributed graph data storage: On the basis of the traditional graph database, the graph structure data and property data are stored and the same data copy is stored on each node.
- Structured property co-storage: With external storage such as ElasticSearch and Solr, we can achieve the storage and index construction of large-scale structured property data.
- BLOB storage: In storage systems such as Hbase and Ceph, the unstructured property data can be stored in a distributed manner.
The overall architecture of PandaDB is illustrated in Figure 5, and the important modules are described below.
- Storage engine: This module maintains local graph structure data, schedules external property storage and provides services for the query engine on demand.
- External storage: This module includes two parts: ElasticSearch-based structured property co-storage and HBase-based BLOB storage.
- Query engine: This module parses and executes CypherPlus queries.
- AIPM: This module is a service framework of AI models, which realizes the flexible deployment of AI models and efficient on-demand running through model and resource management. Besides, it effectively shields the dependence between AI models.
The PandaDB cluster adopts a master-less architecture. In Figure 1, PandaNode is one of the nodes with a query engine and a storage engine. Property data and unstructured data are stored in external distributed storage tools. PandaNode only saves graph structure data and interacts with external storage through the property storage interface.
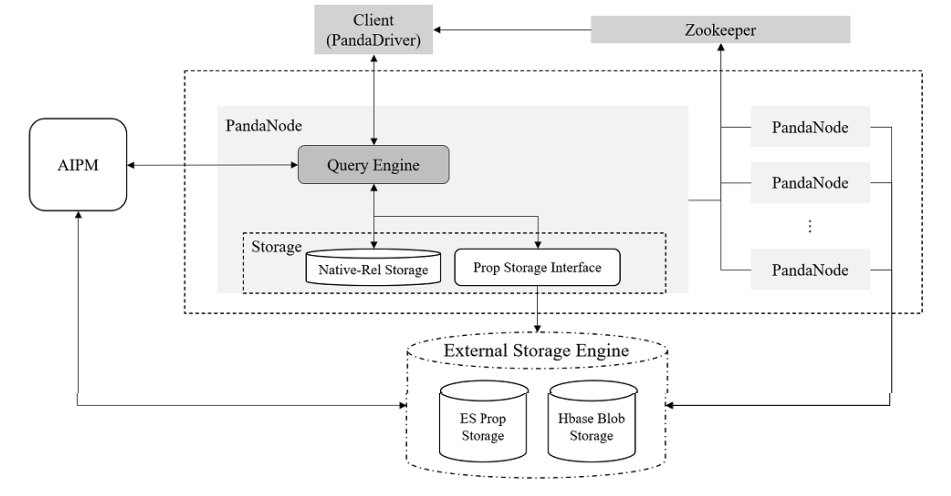
Figure 1. Architecture of PandaDB
Storage mechanism
PandaDB introduces BLOB into the type system of Neo4j and modifies the storage structure of Neo4j at the same time. The storage structure is shown in Figure 2. In addition to Neo4j reserved area, the property fields of BLOB also record the metadata of BLOB, including the unique identifier blobid, length and MIME type.
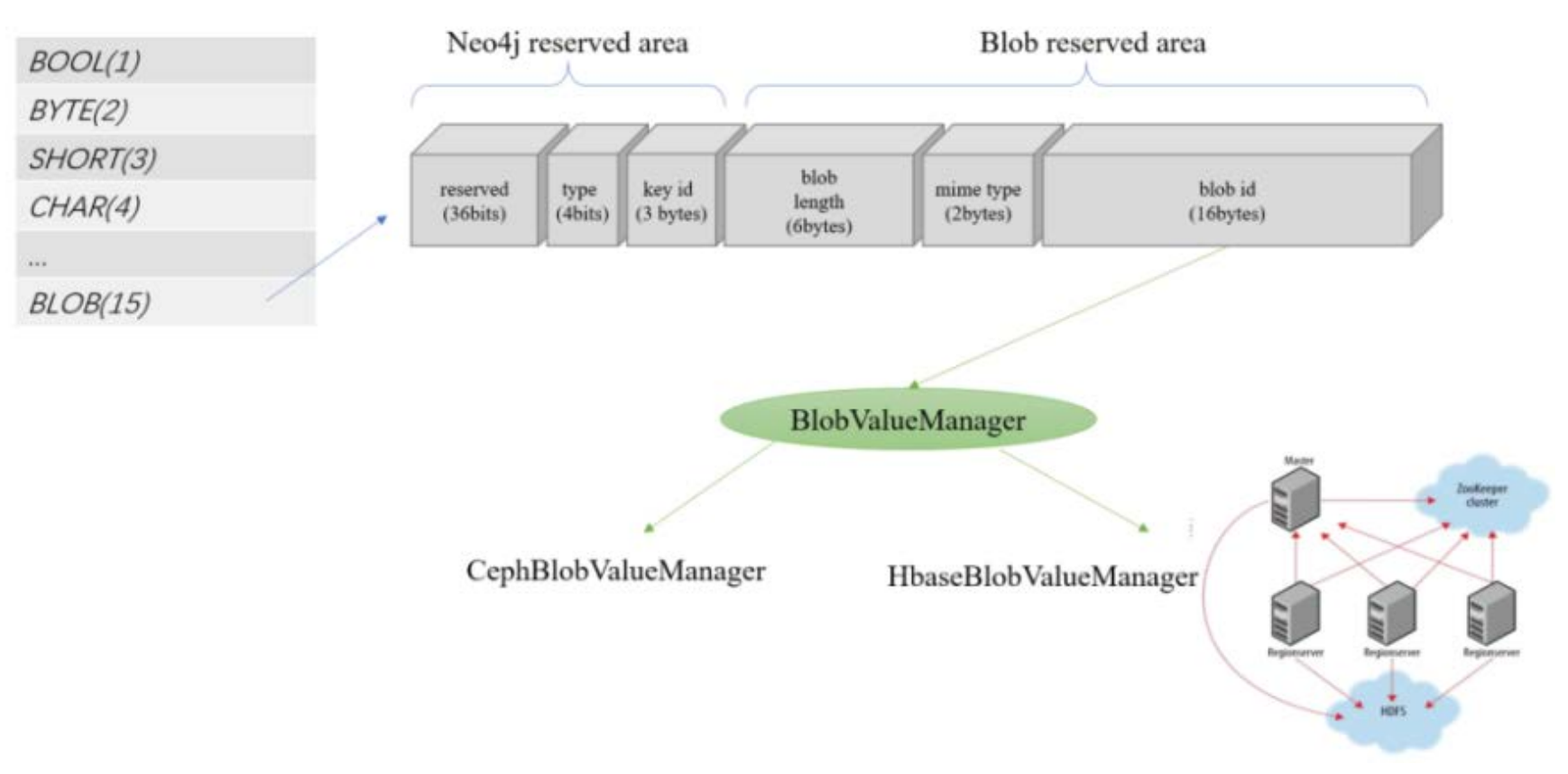
Figure 2. Design of BLOB storage structure
To invoke the external BLOB storage system, PandaDB designs BlobValueManager interface, and defines getById(⋅)/store(⋅)/discard(⋅) and other operation methods. As an implementation of BlobValueManager, HBaseBlobValueManager accesses BLOB data with the HBase cluster. In this plan, HBase is designed as a wide table containing N columns so as to support large-scale BLOB storage. blobid/N is taken as the rowkey of HBase andblobid%N corresponds to a certain column of HBase.
We encapsulate the content reading of BLOB as an InputStream to speed up the reading of BLOB. When users acquire BLOB content or perform semantic computation through the Bolt protocol, this streaming read mechanism improves the performance of the operation.
Multiple storage complicates storage transaction guarantees. When the client writes data, it sends a writing operation request to the Leader node of PandaDB, which then performs the specific writing operation. The specific operation process of the Leader node is as follows.
- The Leader node starts the transaction, executes Cypher analysis and translates the transaction into specific execution operations.
- A request is sent to BLOB storage engine to perform the writing operation of BLOB data. If the execution fails, carry out rolling back upwards and the transaction is marked as failed.
- If the BLOB data is written successfully, the writing operation of graph structure data and structured property data will be executed. If the execution fails, perform rolling back upwards and the transaction is marked as failed.
- The modification of structured property data is synchronized to the co-storage. If the execution fails, carry out rolling back upwards and the transaction is marked as failed.
- The transaction is submitted.
- The transaction is closed and then the return operation succeeds.
Query mechanism
PandaDB query engine mainly aims at the analysis of query statements, the generation and optimization of logical plans, and the optimization and execution of physical plans. On the basis of Neo4j, PandaDB query engine primarily improves the following parts.
- Parsing stage: This stage enhances the parsing rules of Cypher language, supports BLOB literal constant (BlobLiteral), BLOB sub-property extraction operator (SubPropertyExtractor), and property semantic operator (SemanticComparison).
- Grammar inspection stage: This stage performs formal inspections for BlobLiteral, SubPropertyExtractor and SemanticComparison, such as finding illegal BLOB paths, semantic operators and thresholds.
- Plan optimization stage: This stage optimizes the operation of BlobLiteral, and uses predicate pushdown and other strategies for large-scale property filtering situations.
- Plan execution stage: This stage fully schedules the property co-storage module, AIPM module and BLOB storage module to achieve efficient property priority filtering, BLOB acquisition and semantic computation. Figure 3 shows a typical query process that requires returning all nodes that are similar to the face in photo0 and have an age value greater than 30.
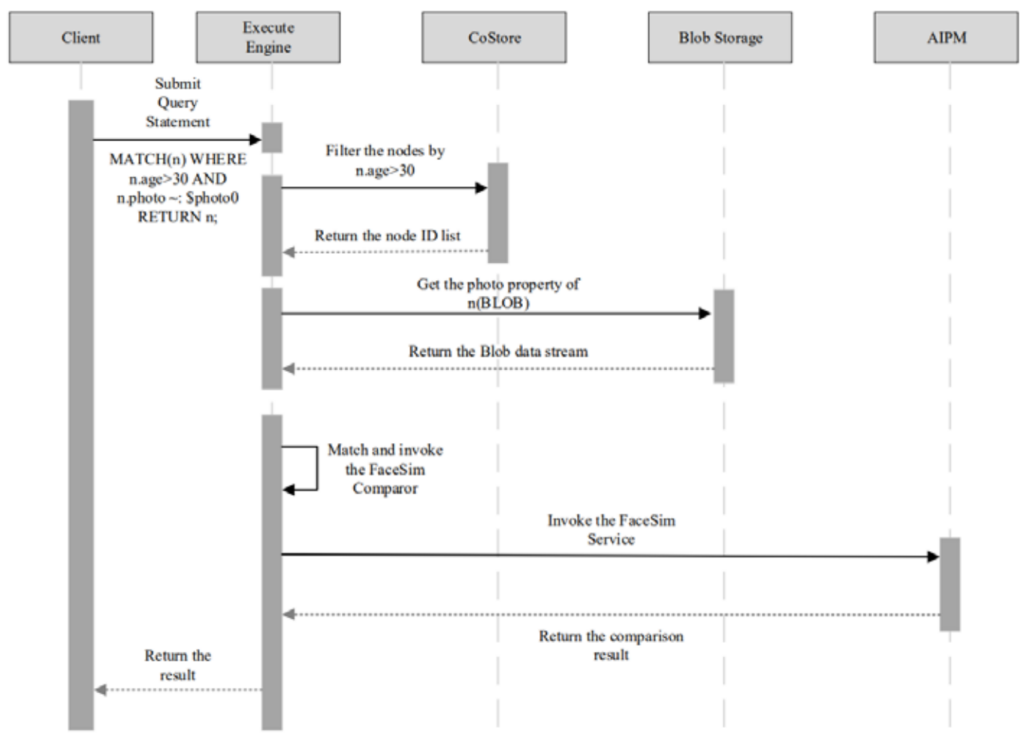
Figure 3. CypherPlus query process
Figure 4 shows the design of query mechanism of PandaDB from the three levels: query syntax, query plan, and execution engine. The parsing engine converts the symbols in the query statement into semantic operators, and the execution engine selects the AI model to process the corresponding data according to the rule set and returns the result.
To speed up the query of unstructured data, PandaDB implements a semantic index function. The information in unstructured data is considered to be a kind of semantic information, such as the face in the image, the license plate number of the car in the image and the text information contained in the recording. The extraction of information from unstructured data by AI models can be regarded as the mapping of data from high-dimensional space to low-dimensional space, and the result of mapping in the low-dimensional space can be used as the semantic index of the data in this scenario.
For example, in the comparison and query of faces, it is necessary to compare the similarity of faces in different images. Face recognition models are usually used to extract facial features and compare the similarity of the two features. In PandaDB, the facial features represented in vector form are regarded as the semantic index of the unstructured data in the current query scenario. When the system processes a query involving face comparison, it first checks whether there is a corresponding semantic index. If the semantic index corresponding to the query exists, a processing request to AIPM is not sent and the semantic index is compared directly to get the result.
Semantic index can reduce the number of requests made by the query engine for AI services; therefore, repeated data transmissions are avoided and system efficiency is improved.
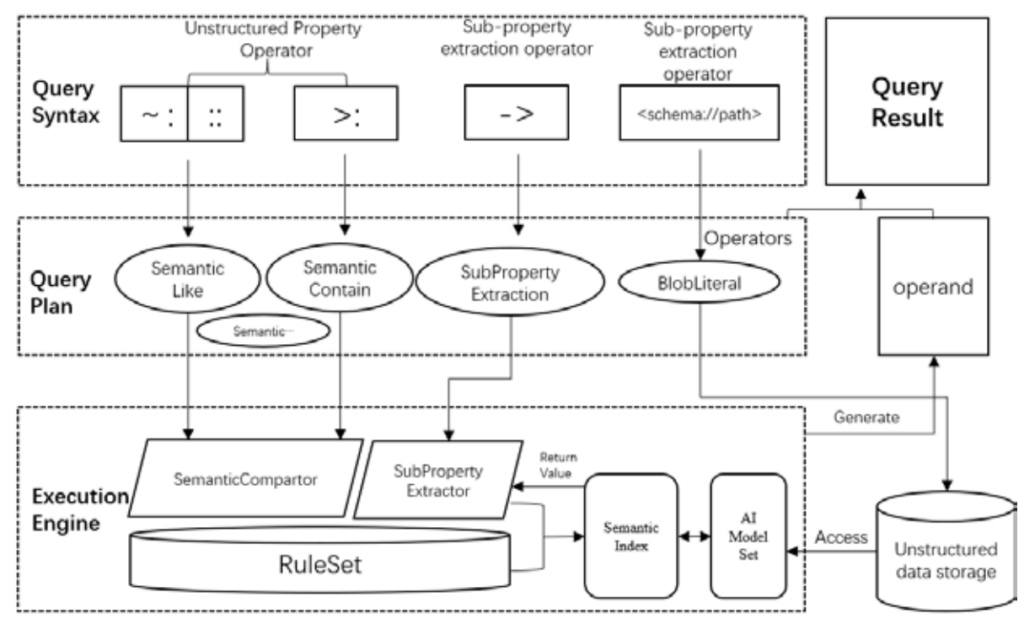
Figure 4. Query mechanism of intelligent property graph
Property data co-storage
PandaDB introduces a property data co-storage mechanism to implement full-text indexing of structured property data and improve the efficiency of filtering and querying node properties. Currently, PandaDB supports ElasticSearch as a co-storage engine.
Figure 5 shows the writing process of the PandaDB co-storage module. The key design of the co-storage mechanism is as follows.
- The storage structure of property data in ElasticSearch: Each Neo4j graph database corresponds to an independent index in the co-storage engine (ElasticSearch). The property data and label data of each node are organized into a document in ElasticSearch. Specifically, the ID, property name and property value of the nodes in the Neo4j database respectively serve as those of the document, and the label data of the nodes is represented as a specially set property label. Numerical values, strings, coordinates, dates, time and other structured property data types are converted to corresponding data types in ElasticSearch.
- Property writing and updating: To maintain the consistency of the local data in Neo4j database and the data in ElasticSearch, PandaDB extends the node update part in the transaction operation execution module (operations) in Neo4j and designs ExternalPropertyStore to store all operations performed in the Neo4j transaction. When Neo4j database performs operations such as inserting nodes, adding tags, setting properties and deleting nodes, it also caches the corresponding operation data in the ExternalPropertyStore. When Neo4j database performs the transaction submission operation, the cached operation data is synchronized to ElasticSearch.
- Property filtering: To achieve node property filtering based on co-storage, PandaDB modifies Cypher query execution plan of Neo4j and pushes down the node property filtering predicates to the co-storage management module. According to the predicate filtering conditions, the ElasticSearch search request is generated. Finally, the list of hit documents (nodes) is returned to the query engine for further filtering. To avoid the network transmission delay due to a large number of query results, PandaDB uses the results delivered by asynchronous batching.
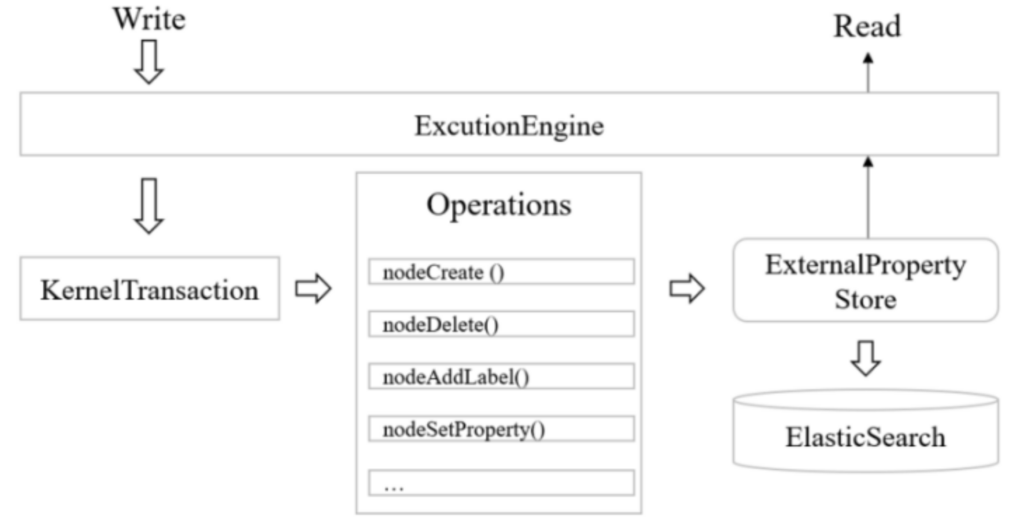
Figure 5. Writing process of property co-storage module in PandaDB